Quebrando o banco: sqlite
Aprendendo sobre o banco sqlite enquanto a gente o quebra
sqlite é um pacote que implementa um banco de dados relacional leve e que não necessita de servidor. Ele é embutido em arquivos e acessar um banco sqlite é equivalente a um fopen.
É importante entender que o sqlite não é um substituto para o Oracle ou PostgreSQL; ele é um substituto para o fopen.
Se o seu projeto precisa de um banco de dados relacional, mas você não quer lidar com a complexidade de gerenciar um servidor, o sqlite é a escolha certa.
Por outro lado, você não deveria usar sqlite ao criar plataformas online. Dependendo da quantidade de usuários, até pode funcionar, mas o mais indicado é utilizar um banco de dados client-server, projetado para lidar melhor com múltiplas conexões concorrentes e altos volumes de leitura e escrita.
ACID
Para ser um banco de dados confiável, o sqlite implementa o conceito de ACID, que é um acrônimo para:
- ATOMicity (Atomicidade): Todas as mudanças acontecem de uma vez, ou nenhuma acontece;
- CONSISTENCY (Consistência): O banco de dados nunca vai estar em um estado inválido;
- ISOLATION (Isolamento): Cada transação acontece de forma isolada, uma não interfere na outra;
- DURABILITY (Durabilidade): No final da operação, as mudanças estão salvas em disco;
ACID é um conjunto de regras que o banco de dados promete fornecer. Ser ACID compliant é garantir que essas regras serão respeitadas. É importante ter em mente que cada banco possui mecanismos próprios para garantir as propriedades ACID. Em bancos SQL, essas garantias são aplicadas por meio de transações, que constituem a base do modelo transacional.
Antes de sair quebrando as coisas, nós vamos passar um tempo tentando entender como transações acontecem dentro do sqlite. Nessa explicação, vou usar muito do conteúdo presente na referência [3].
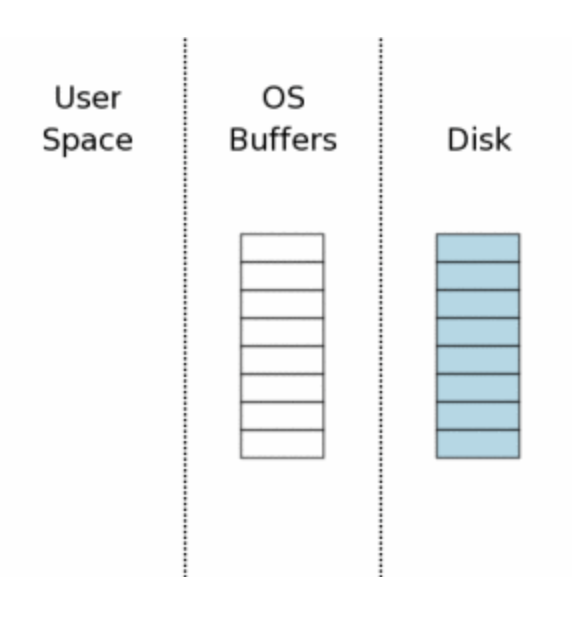
1. Estado inicial
O sqlite precisa de três ambientes diferentes para gerir as suas transações:
- Espaço do usuário, onde a biblioteca sqlite está manipulando os dados; (Representado pelo bloco na esquerda).
- Buffer do sistema, um espaço em memória usado para diminuir a quantidade de leituras no disco; (Representado pelo bloco no meio).
- O disco, espaço na memória física onde os dados são persistidos. (Representado pelo bloco na direita).
Para esse exemplo, vamos supor um estado de cold cache, onde não há nenhuma informação do lado do usuário. Isso significa que toda requisição de leitura precisa ir até o banco de dados no disco.
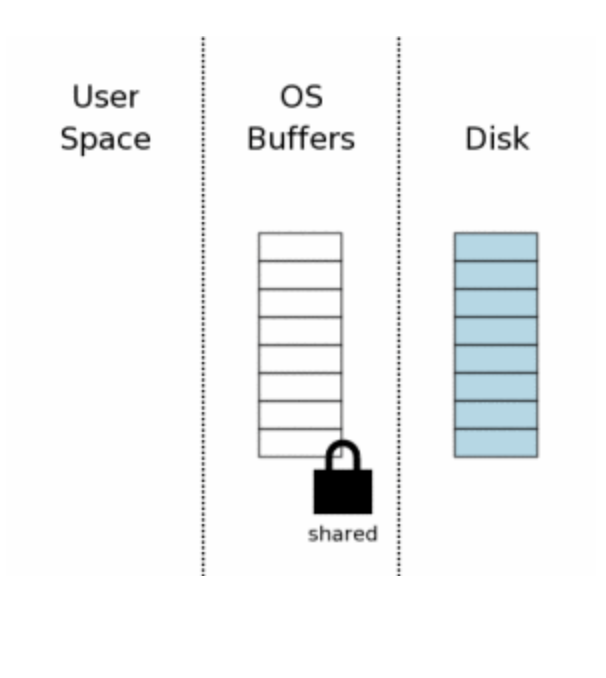
2. Obtendo uma SHARED lock
Para iniciar qualquer escrita no banco, é necessário ler os dados antes. Para poder executar uma leitura, a conexão precisa de uma SHARED lock. Lock é um mecanismo de controle de acessos concorrentes a um banco de dados. A SHARED lock garante o acesso à leitura. É importante ter em mente que muitas conexões podem ter esse nível de lock.
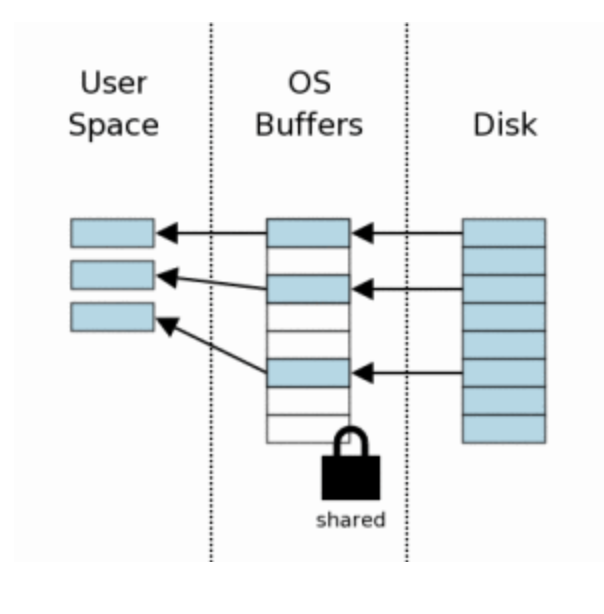
3. Lendo as informações
Após obter a SHARED lock, a leitura pode ser feita. Como o estado inicial é de cold cache, primeiro a leitura é feita no disco, daí os dados são inseridos no buffer do sistema (cache) e, por último, a informação chega ao sqlite3. Próximas leituras poderão pegar dados do cache.
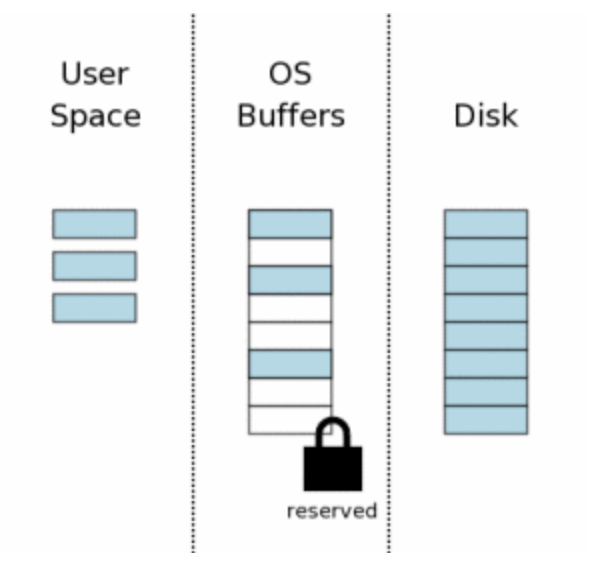
4. Obtendo uma RESERVED lock
O sqlite precisa pegar a RESERVED lock antes de fazer qualquer mudança. Esse lock pode coexistir com várias conexões carregando SHARED locks, mas apenas uma conexão pode ter a RESERVED.
Essa chave indica que a conexão pretende fazer mudanças, mas ainda não começou. Outras conexões podem continuar lendo.
5. Criando um rollback journal file
Antes de modificar qualquer dado no arquivo de banco de dados original, o sqlite cria um arquivo separado chamado "rollback journal". Este arquivo conterá o estado original das páginas que serão modificadas.
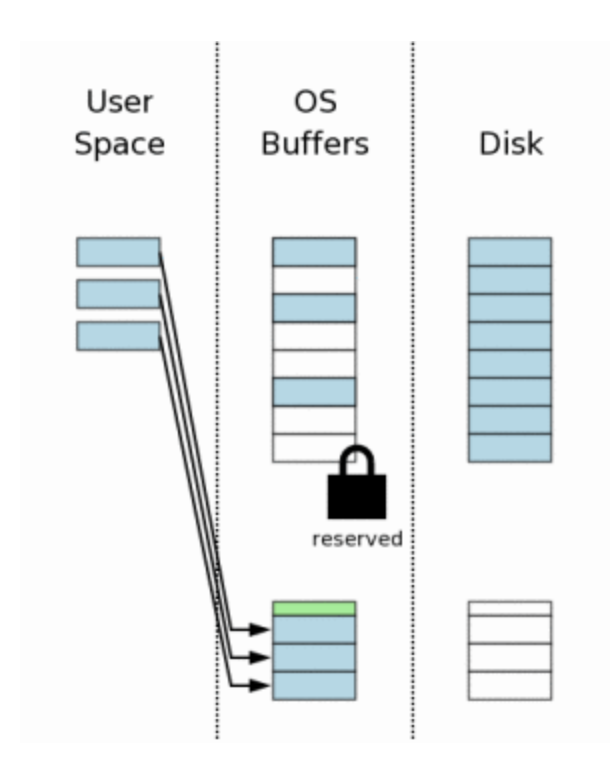
6. Mudando os dados do lado do usuário
As alterações começam a ser feitas na memória privada do processo (User Space). O banco de dados no disco e o cache do sistema ainda permanecem com os dados originais.
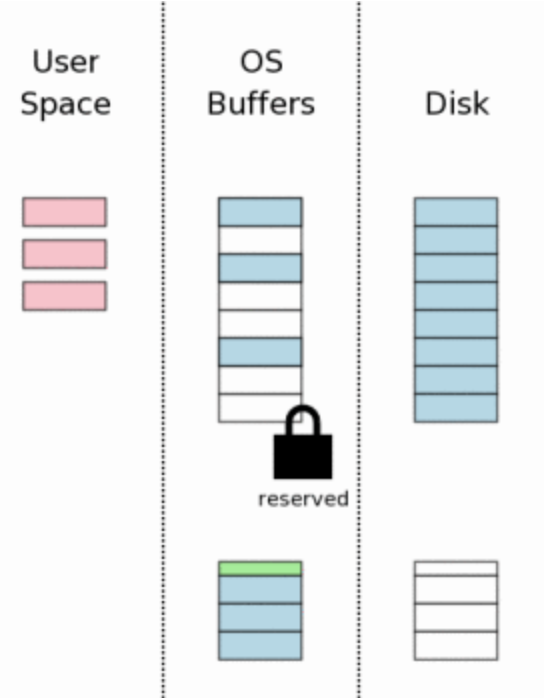
7. Mudando o journal no disco
Para garantir a durabilidade, o sqlite força a escrita do arquivo de rollback journal no disco físico. Isso é crucial para que o banco possa se recuperar caso ocorra uma falha logo em seguida.
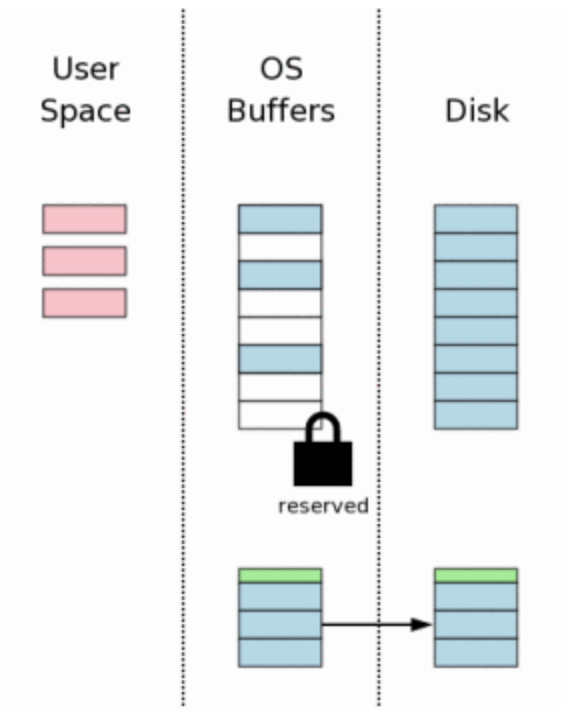
8. Obtendo uma chave exclusiva
Agora o sqlite precisa de um EXCLUSIVE lock. Com este lock, nenhuma outra conexão pode sequer ler o banco de dados. Este é o momento onde a escrita real no arquivo principal vai começar.
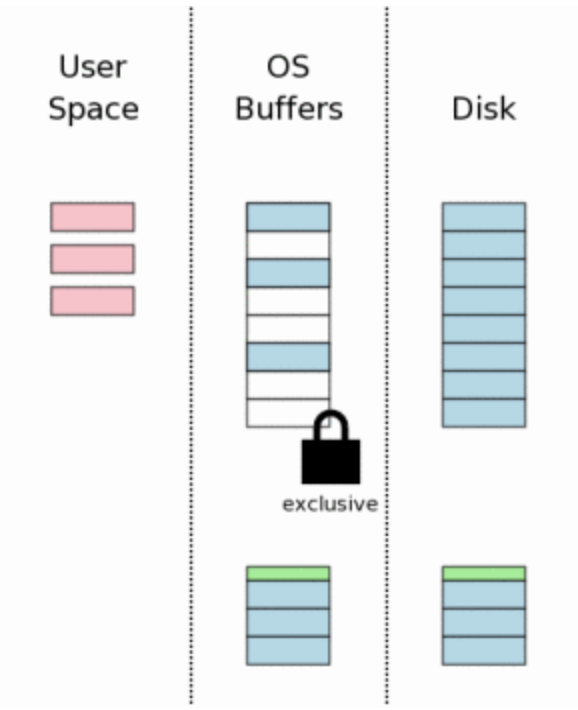
9. Mudando os dados no cache
Os dados modificados são movidos do espaço do usuário para o buffer do sistema (cache). Eles ainda não estão no disco físico, mas já saíram da memória privada da aplicação.
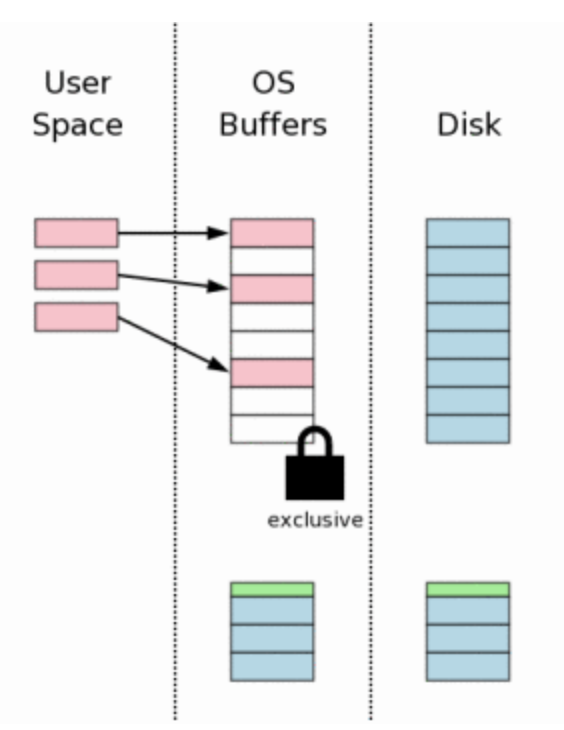
10. Mudando os dados no disco
O sqlite agora instrui o sistema operacional a persistir as mudanças no arquivo de banco de dados real. Este é o passo onde os bits são fisicamente alterados no disco.
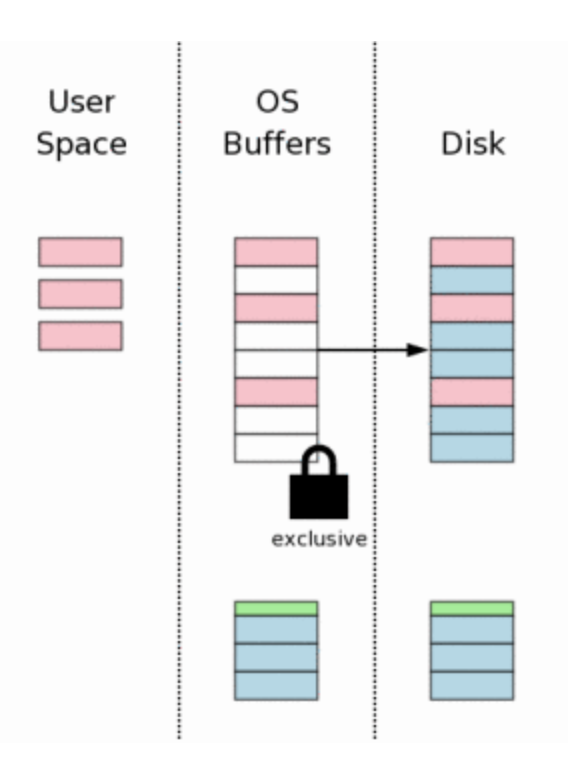
11. Deletando o Rollback journal
Este aqui é um ponto crítico: se a luz acabar antes dos journals serem deletados, o banco pode estar em um estado inconsistente. Por esse motivo, quando uma nova conexão for aberta, o rollback será feito com os dados presentes no journal e, em seguida, o journal será deletado.
Se a luz acabar após o journal ser deletado, a próxima conexão não vai encontrar os journals e nenhum rollback será feito.
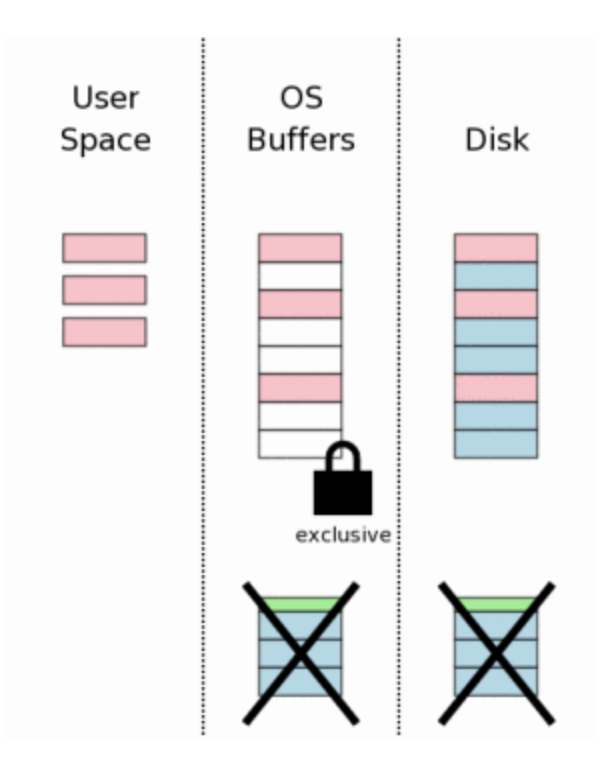
12. Soltando o lock
O último passo é soltar a EXCLUSIVE lock, liberando para outras conexões pegarem uma SHARED ou RESERVED lock.
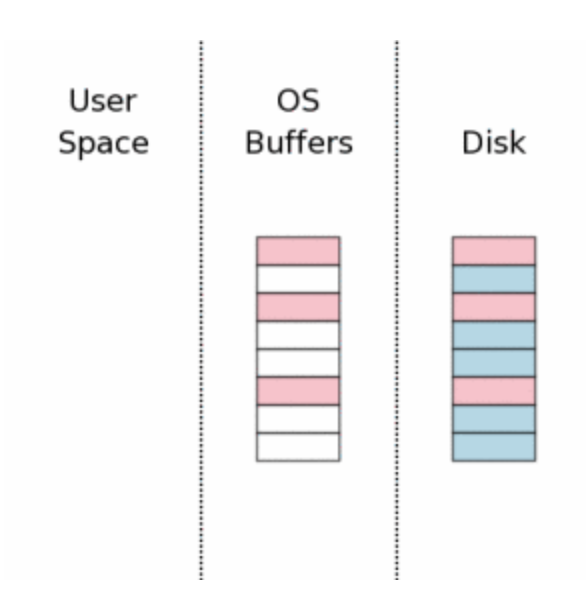
Ainda há muito mais para se aprender sobre sqlite. Dê uma olhada nas referências abaixo caso esteja curioso, mas o que sabemos já é o bastante para saber o que podemos quebrar.
Quebrando coisas
Para poder ter alguns itens numa tabela, em todos os experimentos abaixo eu irei usar um trecho de código parecido com o abaixo. Durante os exemplos, eu irei omitir todos os init_db e vou focar no experimento em si.
import sqlite3
import os
DB_PATH = "test_lock.db"
def init_db():
if os.path.exists(DB_PATH): # Verifica se o banco já existe
os.remove(DB_PATH) # Caso exista, deleta ele
conn = sqlite3.connect(DB_PATH) # O sqlite cria o banco assim que abrimos a conexão pela primeira vez;
conn.execute("CREATE TABLE items (id INTEGER PRIMARY KEY, name TEXT)")
for i in range(5):
conn.execute("INSERT INTO items (name) VALUES (?)", (f"item-{i}",))
conn.commit()
conn.close()
Pegando uma SHARED lock por tempo demais
O que acontece se um leitor "esquecer" uma transação aberta? Como o sqlite impede que novos escritores entrem enquanto houver leitores ativos, uma única consulta mal escrita pode causar um gargalo de escrita (SQLITE_BUSY) em toda a aplicação.
Eu quero começar vendo um timeout quando a conexão ficar aberta tempo demais em uma leitura:
def reader():
print("[Reader] Connecting...")
conn = sqlite3.connect(DB_PATH, timeout=1) # Aqui eu abro a conexão com um timeout de 1 segundo.
cursor = conn.cursor()
cursor.execute("SELECT * FROM items")
time.sleep(5) # Aqui eu paro o processo por 5 segundos
tasks = cursor.fetchall()
conn.close() # Fecho a conexão apenas 5 segundos depois de aberta
print(tasks)
Output:
[Reader] Connecting...
[(1, 'item-0'), (2, 'item-1'), (3, 'item-2'), (4, 'item-3'), (5, 'item-4')]
Cadê o timeout, Rodrigo? Aqui a gente viu um ponto muito importante: o timeout não é para o tempo de conexão, ele é para o tempo que um lock pode esperar. Para validar isso, precisamos rodar o código abaixo após iniciar a leitura.
import sqlite3
import time
DB_PATH = "test_lock.db"
def writer():
print("[Writer] Connecting...")
time.sleep(1) # Aguarda 1 segundo para dar tempo do reader pegar o SHARED lock.
conn = sqlite3.connect(DB_PATH, timeout=1)
conn.execute("INSERT INTO items (name) VALUES ('new-item')")
conn.commit()
Output:
[Reader] Connecting...
[Writer] Connecting...
sqlite3.OperationalError: database is locked
[(1, 'item-0'), (2, 'item-1'), (3, 'item-2'), (4, 'item-3'), (5, 'item-4')]
Para escrever no banco, a conexão precisa pegar uma EXCLUSIVE lock, porém não pode haver nenhuma SHARED lock ativa para isso acontecer. Nesse experimento, a gente viu o sqlite gerenciando concorrência; na prática, ele não liberou a EXCLUSIVE porque havia uma SHARED ativa.
Pegando duas RESERVED locks simultaneamente
O sqlite permite vários leitores, mas apenas um escritor "pretendente". Vamos simular o que acontece quando dois processos tentam iniciar uma escrita ao mesmo tempo e como o banco decide quem ganha e quem recebe o erro.
def writer_1():
print("[Writer 1] Connecting...")
time.sleep(1)
conn = sqlite3.connect(DB_PATH, timeout=1)
conn.execute("BEGIN IMMEDIATE") # Obtém uma RESERVED lock manualmente.
time.sleep(10)
conn.close()
print("[Writer 1] Closing...")
def writer_2():
print("[Writer 2] Connecting...")
conn = sqlite3.connect(DB_PATH, timeout=1)
conn.execute("BEGIN IMMEDIATE") # Obtém uma RESERVED lock manualmente.
conn.close()
print("[Writer 2] Closing...")
Output:
[Writer 1] Connecting...
[Writer 2] Connecting...
sqlite3.OperationalError: database is locked
[Writer 1] Closing...
Existem 3 modos de pedir o lock para o sqlite:
- DEFERRED: Esse é o padrão; esse modo não obtém nenhum lock;
- IMMEDIATE: Esse modo obtém uma RESERVED lock, você pode querer usar isso quando tem certeza que vai modificar um campo e quer garantir prioridade na escrita;
- EXCLUSIVE: Esse modo obtém uma EXCLUSIVE lock.
No exemplo acima, a gente pegou o lock manualmente e, como não pode haver duas RESERVED ao mesmo tempo, a segunda retornou erro por conta do timeout.
Lendo antes de um commit
Vamos ver na prática como o sqlite isola completamente o arquivo durante o momento crítico da persistência no disco.
def writer():
print("[Writer] Connecting...")
time.sleep(1)
conn = sqlite3.connect(DB_PATH, timeout=1)
conn.execute("INSERT INTO items (name) VALUES ('new-item')")
cursor = conn.cursor()
cursor.execute("SELECT * FROM items")
tasks = cursor.fetchall()
print(tasks)
time.sleep(10)
conn.commit()
conn.close()
print("[Writer] Closing...")
def reader():
print("[Reader] Connecting...")
time.sleep(1)
conn = sqlite3.connect(DB_PATH, timeout=1)
cursor = conn.cursor()
cursor.execute("SELECT * FROM items")
tasks = cursor.fetchall()
print(tasks)
conn.close()
print("[Reader] Closing...")
Output:
[Writer] Connecting...
[(1, 'item-0'), (2, 'item-1'), (3, 'item-2'), (4, 'item-3'), (5, 'item-4'), (6, 'new-item')]
[Reader] Connecting...
[(1, 'item-0'), (2, 'item-1'), (3, 'item-2'), (4, 'item-3'), (5, 'item-4')]
[Reader] Closing...
[Writer] Closing...
Aí a gente conseguiu ver na prática o isolamento durante um commit: a conexão 2 não viu o item 6 antes da conexão 1 fazer o commit.
Journal órfão
Simulando um kill -9 no processo após a criação do journal, mas antes do commit final.
O objetivo é ver o mecanismo de recuperação automática do sqlite entrando em ação na próxima conexão, usando o journal para restaurar o banco.
def writer():
print("[Writer] Connecting...")
time.sleep(1)
conn = sqlite3.connect(DB_PATH, timeout=1)
conn.execute("INSERT INTO items (name) VALUES ('new-item')")
time.sleep(10)
# Aqui eu fechei o terminal
conn.commit()
conn.close()
print("[Writer] Closing...")
Antes do commit, eu fechei o terminal que estava com a conexão aberta. Meu plano aqui era ver se o journal ficaria lá até a próxima conexão abrir.
Após abrir uma nova conexão, o sqlite verificou que havia um rollback ativo, daí ele pôde validar se precisava dar rollback em algo e deletou o arquivo.
Conclusão
Nesse artigo a gente viu o que é ACID e como os bancos de dados usam transações pra garantir atomicidade, consistência, isolamento e durabilidade.
Também exploramos como isso funciona no SQLite e fizemos alguns experimentos na prática pra validar a teoria.
Eu até pensei em ir além e testar cenários com concorrência e race conditions, mas o post já ficou grande o suficiente — então vou deixar essa parte pra um próximo.